0. Abstract
본 블로그는 자연어에 대해선 큰 관심이 없지만 attention 메커니즘이 여기저기 쓰이길래 읽었다.
NMT는 최근 제안된 기계번역 approach이다.
NMT에 제안된 모델은 RNN 기반의 encoder-decoder 구조를 갖는다.
- encoder : source sentence ==> (fixed length) encoded vector
- decoder : encoded vector ==> translation
이 논문에선
- fixed-length vector사용이 성능 저하의 원인으로 생각하여,
- target word를 예측하는데 필요한 soruce sentence의 일부분들을 자동으로 찾는 것을 제안한다.
이 방법으로 영어-프랑스어 번역에서 SOTA를 도달했다.
1. Introduction
NMT는 새롭게 뜨는 기계번역 접근이다.
Kalchbrenner and Blunsom (2013),Sutskever et al. (2014) and Cho et al. (2014b)
기존 phrase 단위 번역 시스템과 달리, sentence 단위로 학습한다.
대부분의 NMT는 encoder-decoder 구조이다.
하지만 fixed length vector에 모든 정보가 압축되는 구조라서, 길이가 길어질 경우 성능이 떨어진다.
이 문제를 다루기 위해, align과 translate를 동시에 학습하는 encoder-decoder 모델을 도입했다.
- Source sentence 안에서 가장 관련된 정보를 찾아서
- 이전의 target word와 결합하여 현재의 target word를 예측한다.
이는 긴 문장에 더 적합한 구조이다.
2. Background: Neural Machine Translation
2.1 RNN Encoder-Decoder
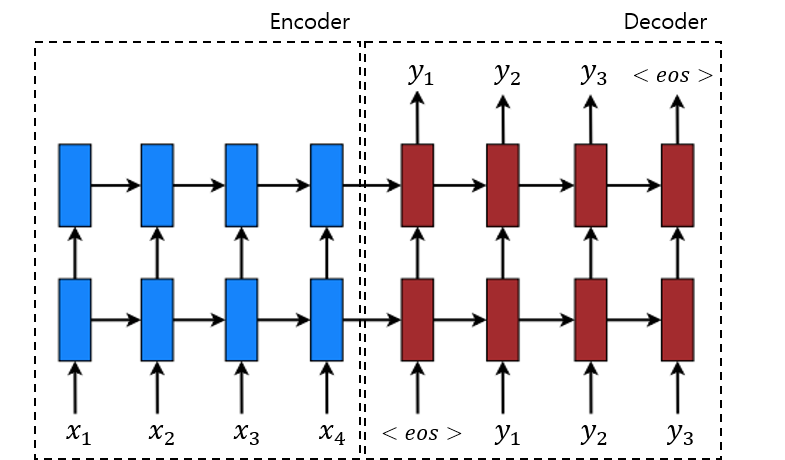
- $\mathbf{x}=\left(x_{1}, \cdots, x_{T_{x}}\right)$ : source sentence
- $h_{t}=\text{RNN}\left(x_{t}, h_{t-1}\right)$ : hidden state
- $c = h_T$ : context vector
- $\mathbf{y}=\left(y_{1}, \cdots, y_{T_{y}}\right)$ : target sentence
- $p(\mathbf{y})=\prod_{t=1}^{T} p\left(y_{t} \mid\left\{y_{1}, \cdots, y_{t-1}\right\}, c\right)$
- $p\left(y_{t} \mid\left\{y_{1}, \cdots, y_{t-1}\right\}, c\right)=g\left(y_{t-1}, s_{t}, c\right)$
- where $g$ is parameterized NN
3. Learning to Align and Translate
이 섹션에서, NMT를 위한 새로운 architecture를 제안한다.
- Bidirectional RNN for encoder
- Search + Translate for decoder
3.1 Decoder : General Description
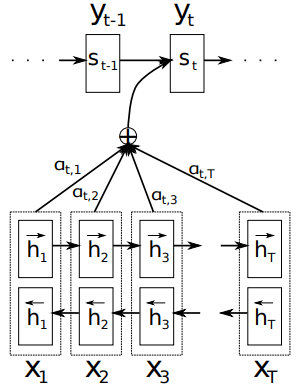
- $s_i = \text{RNN}(y_{i-1}, c_i, s_{i-1})$
- $c_i = \sum_{j=1} ^{T_x} \alpha_{ij} h_j$
- $\alpha_{ij} = \frac{\exp(e_{ij})}{\sum_{k=1}^{T_x}\exp(e_{ik})}$
- $e_{i j}=a\left(s_{i-1}, h_{j}\right)$ where $a$ is an alignment model parameterized by NN
- $p\left(y_{i} \mid y_{1}, \ldots, y_{i-1}, \mathbf{x}\right)=g\left(y_{i-1}, s_{i}, c_{i}\right)$
- where $g$ is parameterized NN
직감적으로, $e_{ij}$는 $y_i$ 생성에 대한 $h_j$의 중요성을 나타낸다.
3.2 Encoder : Bidirectional RNN for Annotating Sequences
일반적인 RNN은 input sequence는 순차적으로 읽으나, $h_j$가
- 이전 문장들을 고려한 $x_j$를 나타내기 보단
- 전체적인 문장 속에서의 $x_j$를 나타내기 위해
bidirectional RNN을 사용했다.
- $\overrightarrow{h}_{1}, \cdots, \overrightarrow{h}_{T_{x}}$ : forward hidden state
- $\overleftarrow{h}_{1}, \cdots, \overleftarrow{h}_{T_{x}}$ : backward hidden state
- $h_{j}=\left[\vec{h}_{j}^{\top} ; \overleftarrow{h}_{j}^{\top}\right]^{\top}$ : annotation for word $x_j$
4. Experiment Settings
ACL WMT ’14 데이터를 싸용했다.
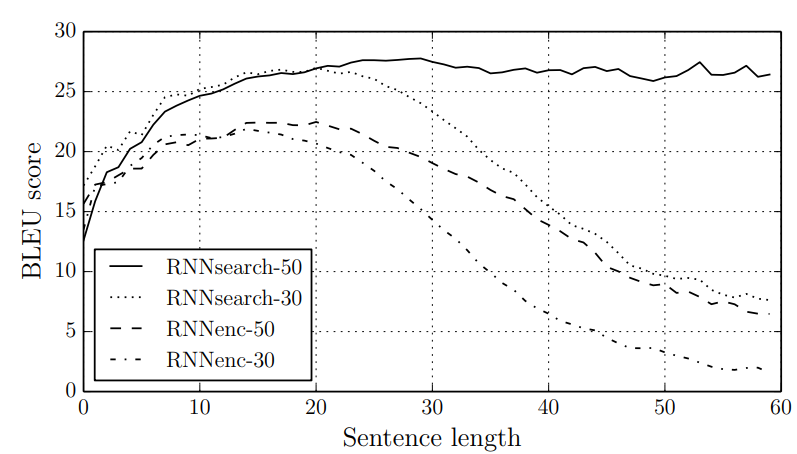
30 word까지만 등장하는 Sentence만 갖고 학습했을 때와, 50 word까지만 등장하는 Sentence를 갖고 학습했을 때의 결과이다.